Tabulky#
S tabulkami se pracuje pomocí knihovny Pandas. Narozdíl od Excelu při práci data v tabulce nevidíme, dokud si je nenecháme vypsat. To ale nevadí. A při rozsáhlých tabulkách to je stejně jedno.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Tabulky z externího souboru#
Častým zdrojem dat je externí soubor. Je možné importovat sešity Excelu, ale nejrychlejší a nejphodlnější je pracovat s csv soubory, což jsou textové soubory s daty oddělenými čárkami. Mohou být na lokálním disku nebo je možné je stáhnout z URL. Po stažení je vhodné si prohlédnout, co máme za data.
zdroj = "https://raw.githubusercontent.com/robert-marik/dmp/main/data/hudson_bay_lynx_hare.csv"
df = pd.read_csv(
zdroj,
skiprows = 2
)
df
| Year | Lynx | Hare | |
|---|---|---|---|
| 0 | 1900 | 4.0 | 30.0 |
| 1 | 1901 | 6.1 | 47.2 |
| 2 | 1902 | 9.8 | 70.2 |
| 3 | 1903 | 35.2 | 77.4 |
| 4 | 1904 | 59.4 | 36.3 |
| 5 | 1905 | 41.7 | 20.6 |
| 6 | 1906 | 19.0 | 18.1 |
| 7 | 1907 | 13.0 | 21.4 |
| 8 | 1908 | 8.3 | 22.0 |
| 9 | 1909 | 9.1 | 25.4 |
| 10 | 1910 | 7.4 | 27.1 |
| 11 | 1911 | 8.0 | 40.3 |
| 12 | 1912 | 12.3 | 57.0 |
| 13 | 1913 | 19.5 | 76.6 |
| 14 | 1914 | 45.7 | 52.3 |
| 15 | 1915 | 51.1 | 19.5 |
| 16 | 1916 | 29.7 | 11.2 |
| 17 | 1917 | 15.8 | 7.6 |
| 18 | 1918 | 9.7 | 14.6 |
| 19 | 1919 | 10.1 | 16.2 |
| 20 | 1920 | 8.6 | 24.7 |
Používáme náhled na začátek souboru, konec souboru, nebo náhodný vzorek. Málokdy nás zajímá celá tabulka, protože může mít tisíce řádků.
df.head() # podobne tail a sample pro konec a nahodny vyber
| Year | Lynx | Hare | |
|---|---|---|---|
| 0 | 1900 | 4.0 | 30.0 |
| 1 | 1901 | 6.1 | 47.2 |
| 2 | 1902 | 9.8 | 70.2 |
| 3 | 1903 | 35.2 | 77.4 |
| 4 | 1904 | 59.4 | 36.3 |
Často nás zajímají základní statistiky pro sloupce tabulky, rozměry tabulky a zda tabulka obdahuje nedefinované hodnoty.
df.describe()
| Year | Lynx | Hare | |
|---|---|---|---|
| count | 21.000000 | 21.000000 | 21.000000 |
| mean | 1910.000000 | 20.166667 | 34.080952 |
| std | 6.204837 | 16.656000 | 21.413982 |
| min | 1900.000000 | 4.000000 | 7.600000 |
| 25% | 1905.000000 | 8.600000 | 19.500000 |
| 50% | 1910.000000 | 12.300000 | 25.400000 |
| 75% | 1915.000000 | 29.700000 | 47.200000 |
| max | 1920.000000 | 59.400000 | 77.400000 |
# počet řádků a sloupců
df.shape
(21, 3)
# True, pokud nějaká hodnota v tabulce chybí
df.isnull().values.any()
np.False_
Grafy#
Dobrý přehled o datech v tabulce dávají grafy. Zpravidla jeden sloupec tabulky obsahuje data pro vodorovnou osu a další sloupce pro svislou osu.
df.plot(x="Year")
<Axes: xlabel='Year'>
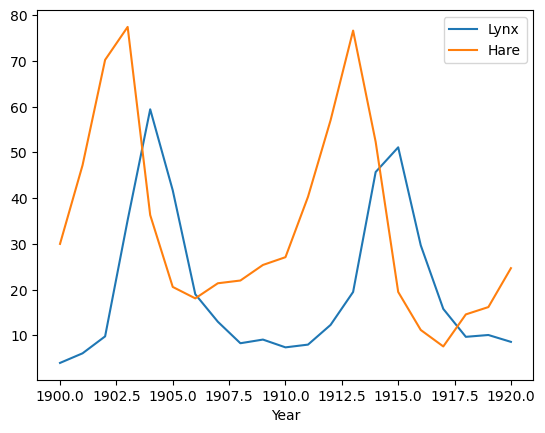
Někdy je vhodné ručně nastavit typ dat ve sloupcích. Například roky neni vhodné brát jako čísla, ale jako časový údaj. Popisky os jsou potom rozumnější.
df.dtypes
Year int64
Lynx float64
Hare float64
dtype: object
# Převod čísel pro letopočty na datový typ datetime.
df.Year = pd.to_datetime(df.Year, format='%Y')
df.dtypes
Year datetime64[ns]
Lynx float64
Hare float64
dtype: object
df.plot(x="Year")
<Axes: xlabel='Year'>
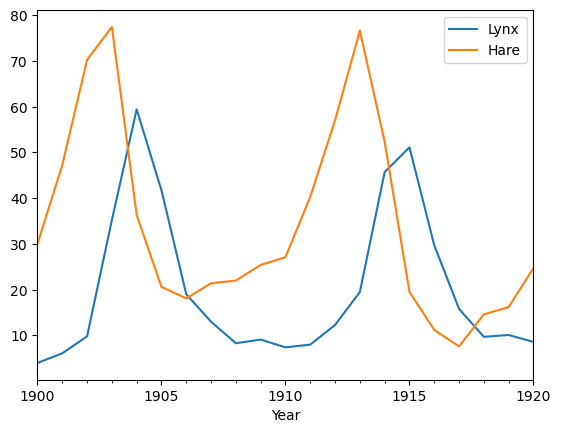
from matplotlib.ticker import MultipleLocator
ax = df.plot(x="Year", subplots = True)
for a in ax:
a.set(ylim=(0,None))
a.grid(which='both')
a.yaxis.set_minor_locator(MultipleLocator(5))
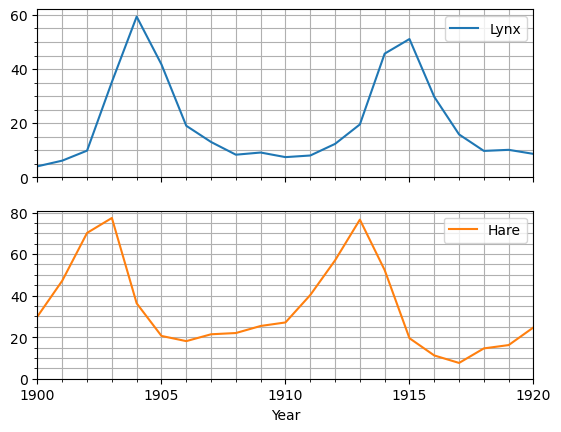
Tvorba tabulek#
Možností jak vytvořit tabulku je celá řada. Taždá možnost se hodí v jiné situaci. V zásadě můžeme buď přidávat sloupec po sloupci, nebo sestavit nějakou strukturu obsahující všechna data a z nich poté sestavit tabulku. Pokud uvedená struktura neumí pracovat se jmény sloupců. je nutné jména sloupců nastavit po vytvoření tabulky.
Možnost 1#
Je možné nejprve vytvořit prázdnou tabulku a po sloupcích připojovat data. Sloupce musí být stejně dlouhé. Jméno sloupce definujeme při jeho vzniku.
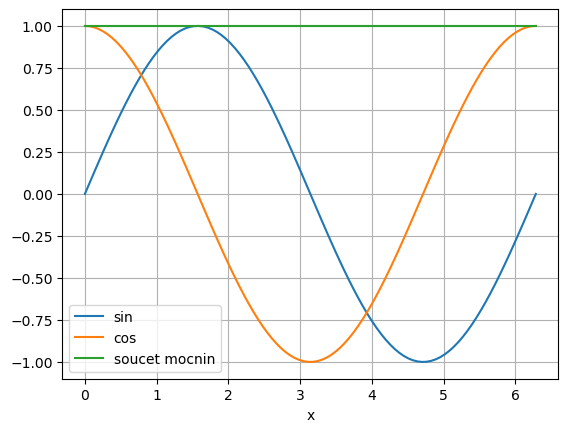
x = np.linspace(0,2*np.pi,100)
df = pd.DataFrame()
df["x"] = x
df["sin"] = np.sin(x)
df["cos"] = np.cos(x)
df["soucet mocnin"] = ( df["sin"] )**2 + ( df["cos"] )**2
df.plot(x="x", grid=True)
df.sample(5)
| x | sin | cos | soucet mocnin | |
|---|---|---|---|---|
| 44 | 2.792527 | 0.342020 | -0.939693 | 1.0 |
| 8 | 0.507732 | 0.486197 | 0.873849 | 1.0 |
| 21 | 1.332797 | 0.971812 | 0.235759 | 1.0 |
| 9 | 0.571199 | 0.540641 | 0.841254 | 1.0 |
| 2 | 0.126933 | 0.126592 | 0.991955 | 1.0 |
Možnost 2#
Další možnost je načíst data ze seznamu. Pokud jsou v seznamu data po řádcích, je nutné je převést do sloupců transponováním. Poté nastavíme jména sloupců.
x = np.linspace(0,2*np.pi,100)
data = [
np.sin(x),
np.cos(x),
np.sin(x)**2+np.cos(x)**2
]
df = pd.DataFrame(np.array(data).T,
index=x,
columns = ["sin","cos","soucet mocnin"]
)
df.plot(grid=True)
df.sample(5)
| sin | cos | soucet mocnin | |
|---|---|---|---|
| 2.094395 | 0.866025 | -0.500000 | 1.0 |
| 2.665594 | 0.458227 | -0.888835 | 1.0 |
| 3.681058 | -0.513677 | -0.857983 | 1.0 |
| 4.569589 | -0.989821 | -0.142315 | 1.0 |
| 4.950388 | -0.971812 | 0.235759 | 1.0 |
Možnost 3#
Jiná možnost je použitím datového typu dictionary. Jména sloupců nastavujeme při tvorbě dictionary. Data do dictionary je možné nastavit najednou, nebo položku po položce.
x = np.linspace(0,2*np.pi,100)
data = {
"sin":np.sin(x),
"cos":np.cos(x),
"soucet mocnin":np.sin(x)**2+np.cos(x)**2
}
df = pd.DataFrame(data, index=x)
df.plot(grid=True)
df.sample(5)
| sin | cos | soucet mocnin | |
|---|---|---|---|
| 5.458121 | -0.734592 | 0.678509 | 1.0 |
| 0.761598 | 0.690079 | 0.723734 | 1.0 |
| 1.459730 | 0.993838 | 0.110838 | 1.0 |
| 3.871458 | -0.666769 | -0.745264 | 1.0 |
| 3.300259 | -0.158001 | -0.987439 | 1.0 |
x = np.linspace(0,2*np.pi,100)
data = {}
data["sin"] = np.sin(x)
data["cos"] = np.cos(x)
data["soucet mocnin"]=np.sin(x)**2+np.cos(x)**2
df = pd.DataFrame(data, index=x)
df.plot(grid=True)
df.sample(5)
| sin | cos | soucet mocnin | |
|---|---|---|---|
| 2.855993 | 0.281733 | -0.959493 | 1.0 |
| 5.775453 | -0.486197 | 0.873849 | 1.0 |
| 2.665594 | 0.458227 | -0.888835 | 1.0 |
| 0.253866 | 0.251148 | 0.967949 | 1.0 |
| 2.030929 | 0.895994 | -0.444067 | 1.0 |