Hierarchický index (pokročilí)#
Pokročilejší práce s multiindexem (hierarchický index).
Vyřešíme soustavu rovnic. Naučíme se uložit data do tabulky, kde budou přístupné výsledky pro jednotlivá nastavení modelu (datasety) a pro vývoj jednotlivých populací.
Naučíme se uložená data vyvolávat a používat například pro tvorbu grafů.
Nejprve import knihoven a nastavení.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.integrate import solve_ivp
def konkurence(t,X,a=1,b=1,c=0.4,alpha=1,beta=.2,gamma=1):
x,y = X
return [(a-b*x-c*y)*x, (alpha-beta*x-gamma*y)*y]
meze = [0,30]
pocatecni_podminka = [0.2,0.3]
t = np.linspace(*meze,500)
Tvorba tabulky s hierarchickým indexem#
Vytvoříme tabulku se sloupcovým indexem obsahujícím dvě úrovně. Pro začátek uložíme pouze sloupec s časem jako index. Ideální z hlediska rychlosti je vytvořit sloupce současně s tabulkou a poté do nich jenom vkládat data, ale je možné sloupce vytvářet i později.
my_index = pd.MultiIndex.from_tuples([], names=['dataset', 'populace'])
df = pd.DataFrame(columns=my_index, index=t)
df.index.name = "Čas"
df.tail()
| Čas |
|---|
| 29.759519 |
| 29.819639 |
| 29.879760 |
| 29.939880 |
| 30.000000 |
Dále vyřešíme pro jednotlivá nastavení (bez konkurence, s konkurencí a dominance jednoho a druhého druhu) a vložíme do tabulky. Vytiskneme konec tabulky.
datasets = ["nezávislé populace","slabá konkurence","dominance x","dominance y"] # Názvy datasetů
druhy = ["x","y"] # Názvy druhů
for c,beta,d in zip(
[0,0.4,0.4,1.5], # hodnoty pro koeficient c
[0,0.2,1.3,0.8], # hodnoty pro koeficient beta
datasets # názvy datasetů
):
reseni = solve_ivp(
lambda t,X:konkurence(t,X,c=c,beta=beta),
meze,
pocatecni_podminka,
t_eval=t
).y.T # řešení ve sloupcích
df[[(d,druh) for druh in druhy]] = reseni # uložení do tabulky
df.tail() # tisk konce tabulky pro kontrolu
| dataset | nezávislé populace | slabá konkurence | dominance x | dominance y | ||||
|---|---|---|---|---|---|---|---|---|
| populace | x | y | x | y | x | y | x | y |
| Čas | ||||||||
| 29.759519 | 0.999867 | 0.999926 | 0.652025 | 0.869367 | 0.999876 | 0.000107 | 6.607543e-07 | 0.999999 |
| 29.819639 | 0.999875 | 0.999931 | 0.652022 | 0.869363 | 0.999880 | 0.000105 | 6.411905e-07 | 0.999999 |
| 29.879760 | 0.999882 | 0.999935 | 0.652022 | 0.869363 | 0.999885 | 0.000103 | 6.222057e-07 | 0.999999 |
| 29.939880 | 0.999889 | 0.999938 | 0.652026 | 0.869368 | 0.999889 | 0.000101 | 6.037822e-07 | 0.999999 |
| 30.000000 | 0.999895 | 0.999942 | 0.652032 | 0.869376 | 0.999893 | 0.000099 | 5.859032e-07 | 0.999999 |
Použití dat z tabulky#
Na řadě je vykreslení dat ze sloupců tak, aby byly v jednom obrázku všechna data pro jednotlivé datasety a poté v jedno obrázku všechna data pro jednotlivé populace.
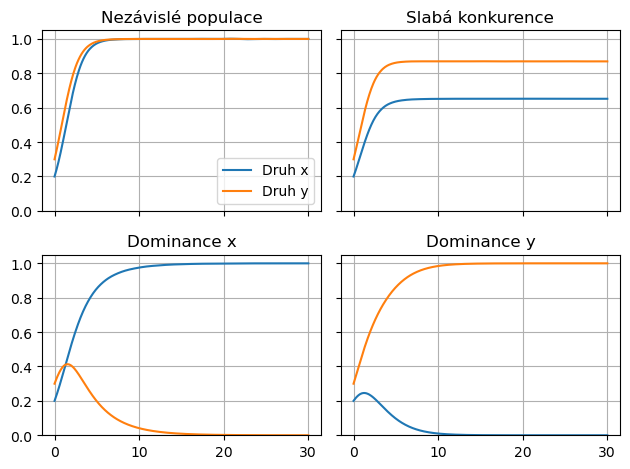
fig,axs = plt.subplots(2,2,sharex=True, sharey=True) # obrázek se čtyřmi podobrázky ve dou řadách a sloupcích
axs = axs.ravel() # abychom se nemuseli na podobrázky odkazovat dvojitým indexem, seřadíme je lineárně
for ax,dataset in zip(axs,datasets): # cyklus přes podobrázky a datasety
ax.plot(t,df.xs(key=(dataset,"x"),level=(0,1),axis=1)) # vykreslení datasetu do podobrázku
ax.plot(t,df.xs(key=(dataset,"y"),level=(0,1),axis=1)) # vykreslení datasetu do podobrázku
ax.set( # nastavení nadpisu
title=dataset.capitalize()
)
ax.grid()
axs[0].set(ylim=(0,1.05)) # rozsah pro svislou osu
axs[0].legend([f"Druh {i}" for i in druhy]) # legenda
plt.tight_layout() # automatické upravení mezer mezi obrázky
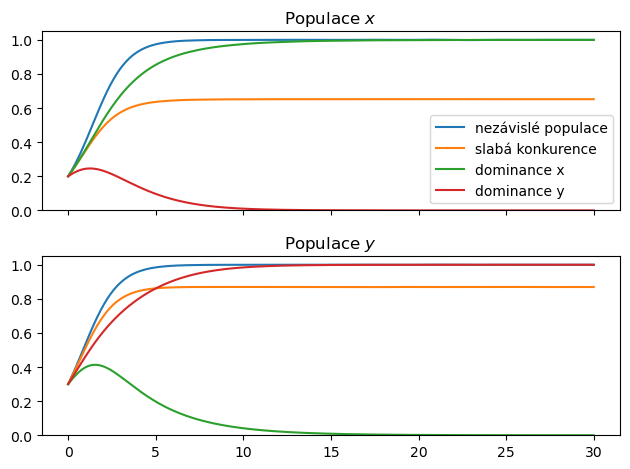
fig,axs = plt.subplots(2,1,sharex=True)
for ax,populace in zip(axs,druhy):
ax.plot(t,df.xs(level=1,axis=1,key=populace))
ax.set(
ylim=(0,1.05),
title=f"Populace ${populace}$",
)
axs[0].legend(datasets)
plt.tight_layout()
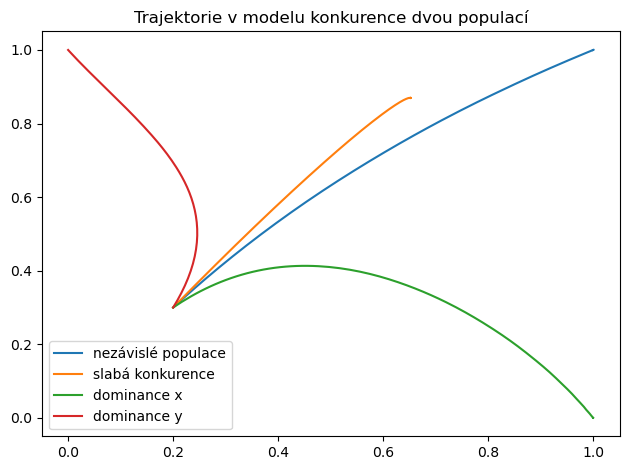
Mírnou modifikací kódu je možné vykreslit trajektorie řešení. (Pozor na to, jedná se o trajektorie pro čtyři různé autonomní systémy, proto trajektorie mohou vycházet z jednoho bodu por různými směry.)
fig,ax = plt.subplots()
for dataset in datasets:
ax.plot(df[dataset,"x"],df[dataset,"y"],label=dataset)
ax.legend()
ax.set(title="Trajektorie v modelu konkurence dvou populací")
plt.tight_layout()
Ukázky selekce sloupců#
Výběr podle hodnoty první úrově indexu je jednoduchý. Vlastně to je stejné jako pro klasické indexy.
Nejprve jak vypadá naše tabulka (začátek).
df.head()
| dataset | nezávislé populace | slabá konkurence | dominance x | dominance y | ||||
|---|---|---|---|---|---|---|---|---|
| populace | x | y | x | y | x | y | x | y |
| Čas | ||||||||
| 0.000000 | 0.200000 | 0.300000 | 0.200000 | 0.300000 | 0.200000 | 0.300000 | 0.200000 | 0.300000 |
| 0.060120 | 0.209793 | 0.312775 | 0.208264 | 0.312015 | 0.208274 | 0.307870 | 0.204138 | 0.309777 |
| 0.120240 | 0.219933 | 0.325841 | 0.216698 | 0.324243 | 0.216741 | 0.315591 | 0.208126 | 0.319622 |
| 0.180361 | 0.230421 | 0.339187 | 0.225294 | 0.336670 | 0.225396 | 0.323143 | 0.211952 | 0.329523 |
| 0.240481 | 0.241253 | 0.352797 | 0.234040 | 0.349277 | 0.234232 | 0.330503 | 0.215607 | 0.339467 |
Následovně se z dat vyfiltrje vývoj systému, kdy sledujeme dvě nezávislé populace.
df["nezávislé populace"]
| populace | x | y |
|---|---|---|
| Čas | ||
| 0.000000 | 0.200000 | 0.300000 |
| 0.060120 | 0.209793 | 0.312775 |
| 0.120240 | 0.219933 | 0.325841 |
| 0.180361 | 0.230421 | 0.339187 |
| 0.240481 | 0.241253 | 0.352797 |
| ... | ... | ... |
| 29.759519 | 0.999867 | 0.999926 |
| 29.819639 | 0.999875 | 0.999931 |
| 29.879760 | 0.999882 | 0.999935 |
| 29.939880 | 0.999889 | 0.999938 |
| 30.000000 | 0.999895 | 0.999942 |
500 rows × 2 columns
Komplikovanější je, když na hodnotě první úrovně indexu nezáleží, ale vybíráme podle druhé úrovně. Možností je několik, jedna z nich je využití příkazu xs. Takto se vyberou sloupce s vývojem první populace pro jednotlivé scénáře (datasety).
df.xs(level=1,axis=1,key="x")
| dataset | nezávislé populace | slabá konkurence | dominance x | dominance y |
|---|---|---|---|---|
| Čas | ||||
| 0.000000 | 0.200000 | 0.200000 | 0.200000 | 2.000000e-01 |
| 0.060120 | 0.209793 | 0.208264 | 0.208274 | 2.041376e-01 |
| 0.120240 | 0.219933 | 0.216698 | 0.216741 | 2.081256e-01 |
| 0.180361 | 0.230421 | 0.225294 | 0.225396 | 2.119524e-01 |
| 0.240481 | 0.241253 | 0.234040 | 0.234232 | 2.156074e-01 |
| ... | ... | ... | ... | ... |
| 29.759519 | 0.999867 | 0.652025 | 0.999876 | 6.607543e-07 |
| 29.819639 | 0.999875 | 0.652022 | 0.999880 | 6.411905e-07 |
| 29.879760 | 0.999882 | 0.652022 | 0.999885 | 6.222057e-07 |
| 29.939880 | 0.999889 | 0.652026 | 0.999889 | 6.037822e-07 |
| 30.000000 | 0.999895 | 0.652032 | 0.999893 | 5.859032e-07 |
500 rows × 4 columns
Pokud vybíráme podle více kritérií, používáme n-tice.
df.xs(level=(0,1),axis=1,key=("slabá konkurence","x"))
| dataset | slabá konkurence |
|---|---|
| populace | x |
| Čas | |
| 0.000000 | 0.200000 |
| 0.060120 | 0.208264 |
| 0.120240 | 0.216698 |
| 0.180361 | 0.225294 |
| 0.240481 | 0.234040 |
| ... | ... |
| 29.759519 | 0.652025 |
| 29.819639 | 0.652022 |
| 29.879760 | 0.652022 |
| 29.939880 | 0.652026 |
| 30.000000 | 0.652032 |
500 rows × 1 columns
Pokud chceme jeden konkrétní sloupec, je možné předchozí kód zjednodušit. Takto se vyberou data odpovídající první populaci při slabé konkurenci. Formálně je výsledek stejný jako v minulém případě, ale protože výsledekem je jeden sloupec, je výsledek ve tvaru vektoru (přesněji řada typu pandas.Series). Předchozí postup pomocí xs vrací tabulku, která by při existenci další hierarchie ve sloupcovém indexu mohla mít více sloupců
df["slabá konkurence","x"]
Čas
0.000000 0.200000
0.060120 0.208264
0.120240 0.216698
0.180361 0.225294
0.240481 0.234040
...
29.759519 0.652025
29.819639 0.652022
29.879760 0.652022
29.939880 0.652026
30.000000 0.652032
Name: (slabá konkurence, x), Length: 500, dtype: float64